
El mundo del aprendizaje automático sigue evolucionando, y con esa evolución surgen nuevas herramientas que facilitan su integración y escalabilidad. Hoy te quiero hablar de Kubeflow, una plataforma que transforma cómo implementamos y gestionamos nuestros modelos de machine learning en un entorno de Kubernetes. Si alguna vez has trabajado con Kubernetes y te has preguntado cómo llevar tus proyectos de machine learning a producción, Kubeflow es tu respuesta.
¿Qué necesitas para este lab?
Como te imaginarás, este workshop está dirigido a ti, que ya tienes cierta experiencia con Kubernetes y estás buscando llevar tus habilidades de machine learning al siguiente nivel. Si estás trabajando en Windows, no te preocupes, vamos a guiarnos por esa ruta. Aquí lo que vas a necesitar:
- Un clúster de Kubernetes. Puedes usar Minikube si estás local o usar algún proveedor en la nube como GKE o EKS.
- kubectl instalado y configurado en tu máquina.
- Familiaridad básica con Python y YAML (si no, tranquilo, iremos por pasos sencillos).
Paso 1: Preparando el entorno en Windows
Para arrancar, vamos a preparar nuestro entorno. Si no tienes Kubernetes corriendo aún en tu Windows, vamos a levantar Minikube, que es una opción sencilla y rápida para trabajar localmente.
Instrucciones:
- Abre tu PowerShell en modo administrador.
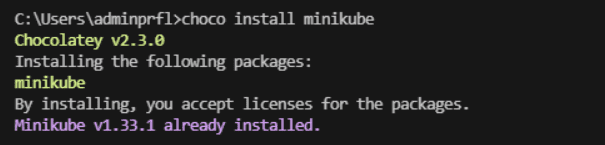
- Instala Minikube ejecutando lo siguiente:
- choco install minikube
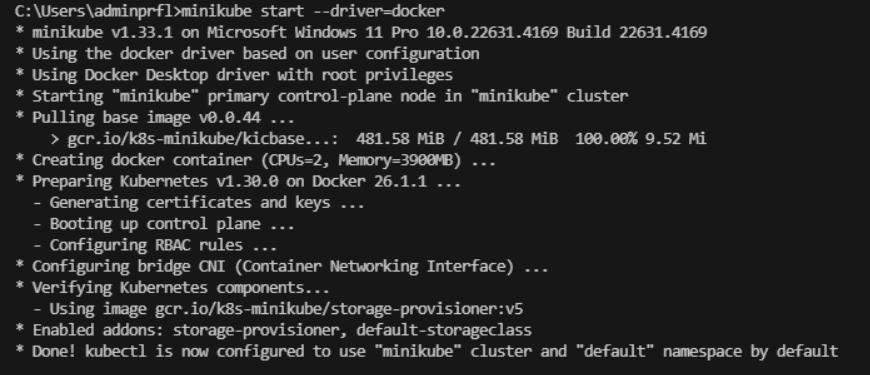
- Inicia tu clúster de Minikube:
- minikube start –driver= docker
Verifica que el clúster esté funcionando:
- kubectl get nodes

Paso 2: Instalando Kubeflow en tu clúster
En este paso, desplegaremos todos los componentes necesarios de Kubeflow en el clúster usando Kustomize y Git. Esto te permitirá gestionar pipelines de machine learning directamente desde Kubeflow.
Instrucciones:
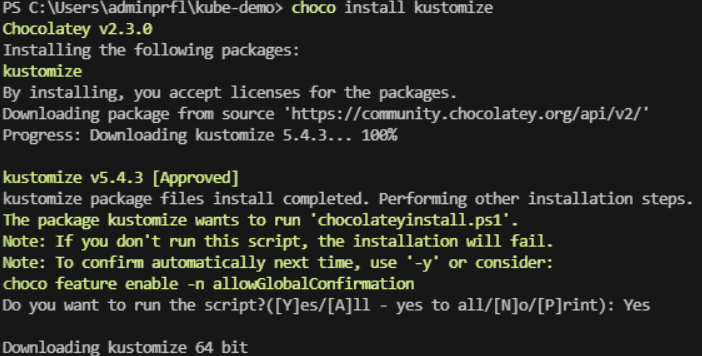
- Instalación de Kustomize:
Ejecuta el siguiente comando en tu PowerShell para instalar Kustomize usando Chocolatey:
- choco install kustomize
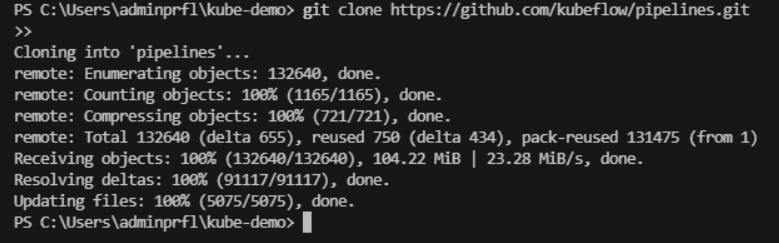
- Clonando el repositorio de Kubeflow Pipelines:
Ahora, clona el repositorio de Kubeflow Pipelines para tener acceso a los manifiestos de Kubernetes necesarios:
- git clone https://github.com/kubeflow/pipelines.git
Este comando descargará todos los archivos necesarios para desplegar los recursos de Kubeflow Pipelines.
- Desplegando los recursos con Kustomize para el clúster:
Luego de clonar el repositorio, navega hasta el directorio de manifiestos (pipelines/manifests) de Kubeflow y ejecuta el siguiente comando para aplicar los recursos en el clúster:
- kustomize build cluster-scoped-resources/ | kubectl apply -f –
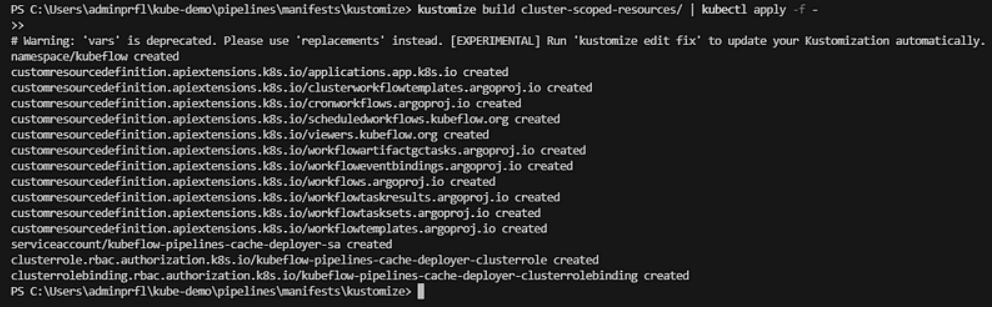
- Desplegar los recursos necesarios para tu entorno:
Ahora, navega a la carpeta de manifiestos y ejecuta el siguiente comando para desplegar los recursos en un entorno agnóstico a la plataforma:
- kustomize build «env/platform-agnostic/» | kubectl apply -f –
Esto comenzará el despliegue de los componentes necesarios de Kubeflow Pipelines en tu clúster. Aquí verás una lista de todos los recursos que se crean, incluyendo serviceaccounts, roles, y bindings.
Una vez finalizado este paso, habrás instalado los componentes clave de Kubeflow.
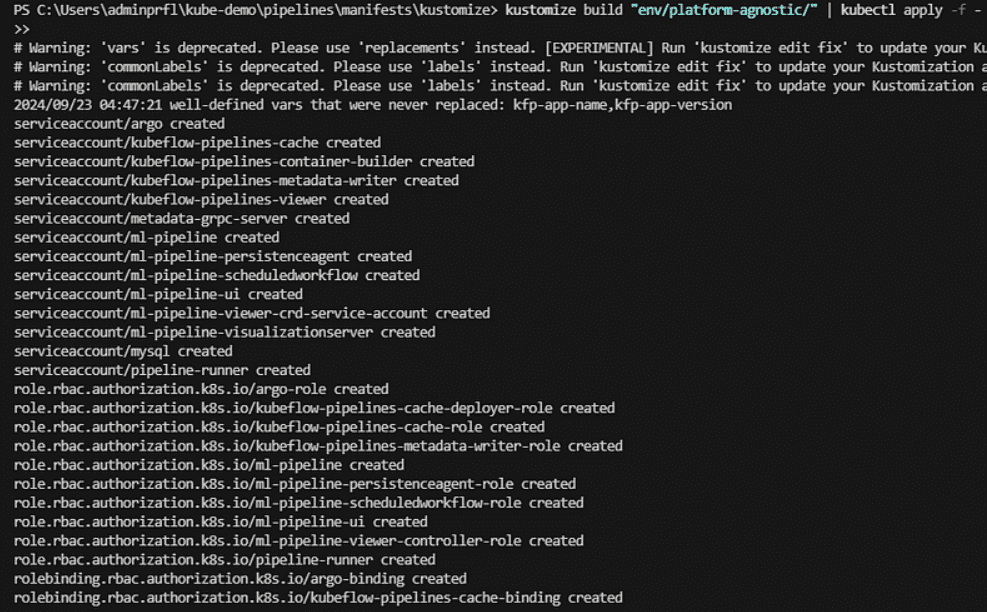
Este comando desplegará todos los componentes necesarios de Kubeflow, y ya estarás listo para trabajar con tus modelos.
Paso 3: Accediendo al Panel de Kubeflow
Kubeflow viene con una interfaz gráfica que hace más amigable el manejo de tus experimentos. Vamos a abrirla y asegurarnos de que todo esté funcionando bien.
Instrucciones:
- Verifica que los pods de Kubeflow estén en ejecución:
- kubectl get pods -n kubeflow
- Exponemos el servicio de acceso al panel (si estás en Minikube):

- Abre tu navegador y visita: http://localhost:8081.
Paso 4: Creando un Pipeline de Machine Learning
Ahora que tienes acceso al panel de Kubeflow, vamos a crear nuestro primer pipeline. Un pipeline es simplemente un conjunto de pasos o tareas que transforman, entrenan y evalúan nuestros modelos de machine learning.
Código de ejemplo para crear el archivo YAML: https://github.com/kubeflow/pipelines/blob/master/samples/core/sequential/sequential.py
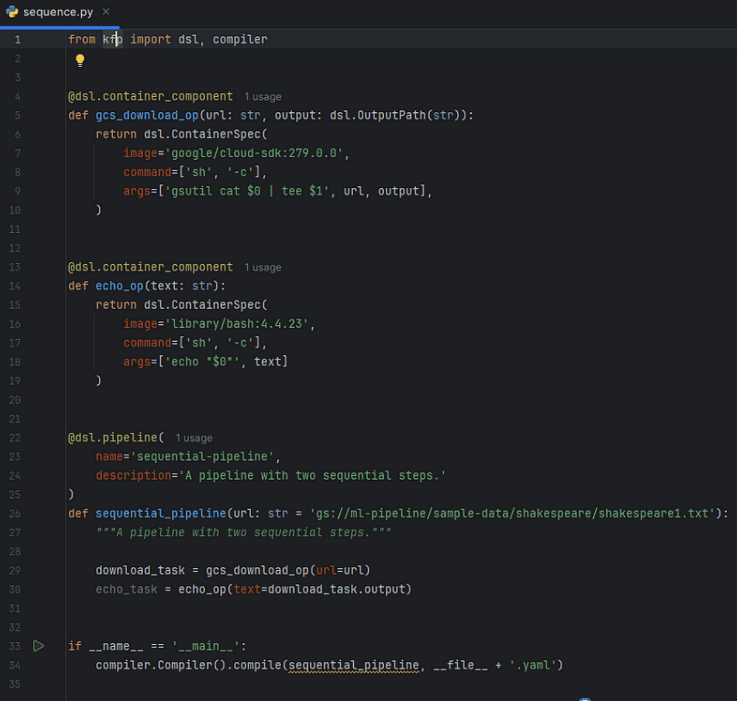
Ahora con el archivo yaml creado, vamos a utilizar el mismo para desplegarlo en el cluster y de esta forma crear ejecuciones para ejecutar en esta caso un proceso secuencial.
Instrucciones:
- Dirígete a la sección de Pipelines para crear un nuevo pipeline usando para ello el archivo yaml creado en el paso previo en el panel de Kubeflow.
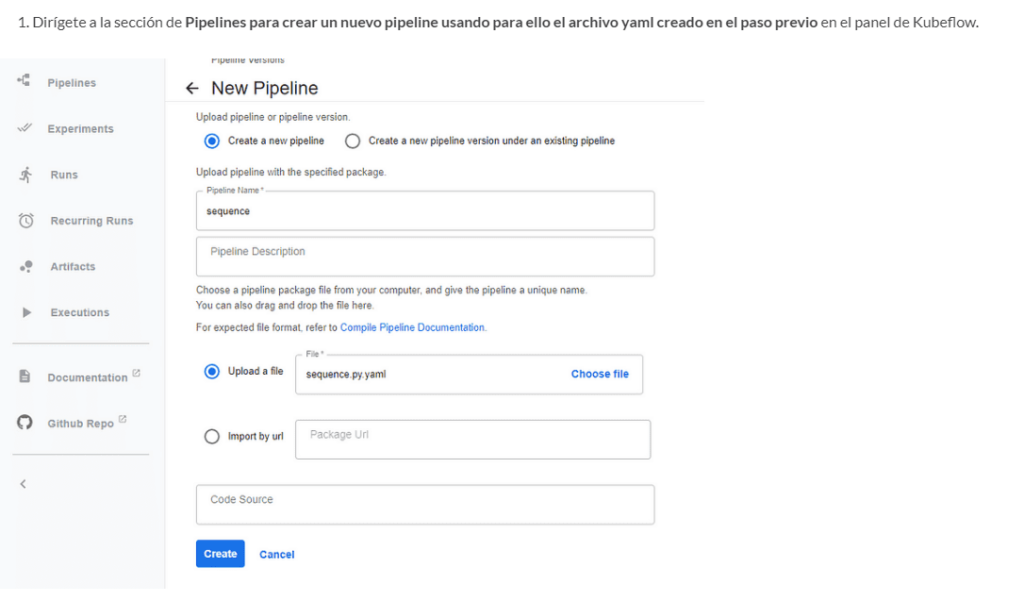
- Inicia el pipeline y sigue el progreso desde el panel. Verás cómo Kubeflow maneja el proceso de entrenamiento en Kubernetes de manera eficiente.
Paso 5: Desplegando tu modelo con Kubeflow Serving
Una vez que tu modelo ha sido entrenado, puedes desplegarlo usando Kubeflow Serving. Este es un paso clave para llevar tu modelo de la fase de desarrollo a la producción.
Instrucciones:
- En el panel de Experimentos, selecciona el pipeline que ejecutaste previamente.
Revisa el estado del pipeline:
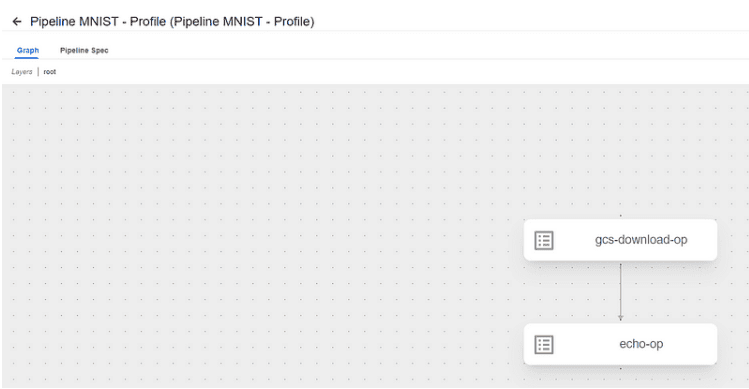
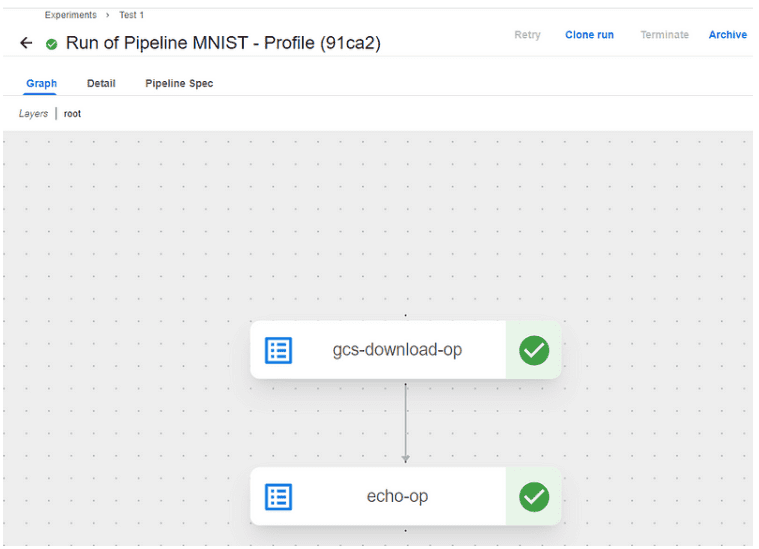
- Después de seleccionar el experimento, verás la visualización de tu pipeline. Cada uno de los componentes del pipeline (por ejemplo, el componente gcs-download-op y echo-op) se representarán en un gráfico de flujo de trabajo.
- Asegúrate de que todas las tareas del pipeline hayan sido ejecutadas correctamente (las casillas de verificación verdes indican que las tareas se completaron sin errores).
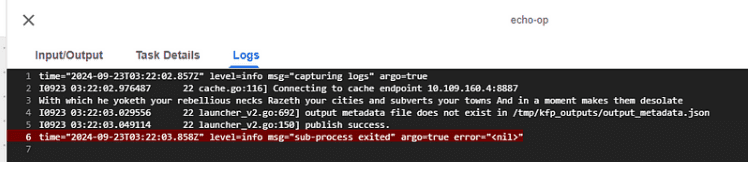
Paso 6: Modelo más avanzado aplicando machine learning:
Desarrolla el componente de entrenamiento:
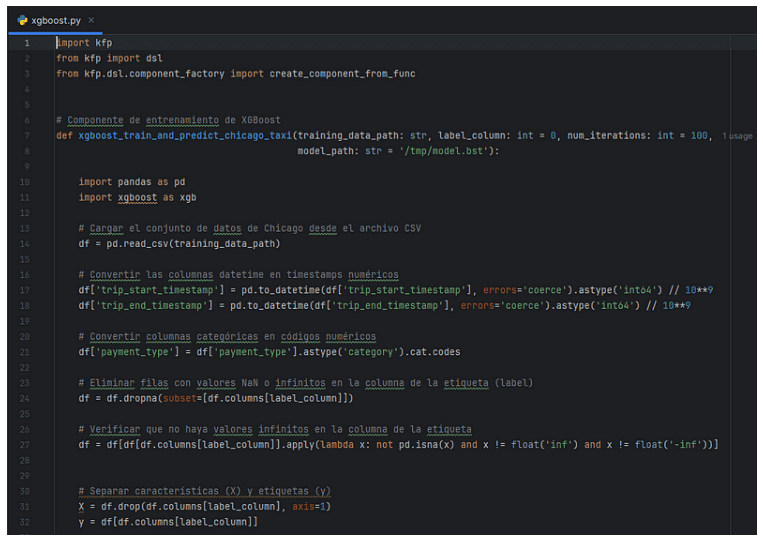
- En el código mostrado en la parte inferior, podemos ver el pipeline creado para entrenar un modelo con XGBoost de predicción de propinas que darán los usuarios a los taxistas en Chicago durante el año 2016.
- El modelo toma como entrada el dataset de taxis de Chicago, que se puede cargar desde una URL pública. El pipeline define la estructura y los parámetros de entrenamiento del modelo, como el número de iteraciones y el objetivo de regresión (reg:squarederror).
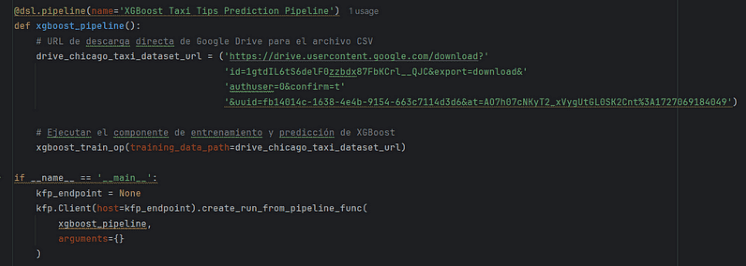
En este ejemplo avanzado hemos creado a través de un script de python y realizado el despliegue automático usando la librería de kfp sin utilizar la consola gráfica.
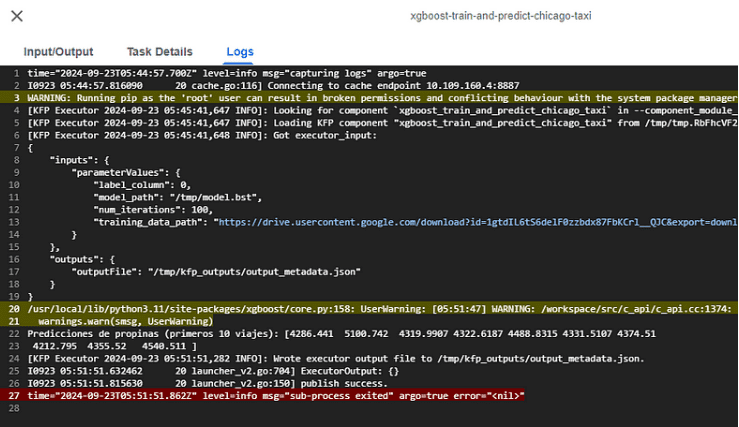
Verificación de los resultados:
- Una vez iniciado el pipeline, revisa los detalles del log en la consola gráfica para verificar que el modelo se haya entrenado correctamente y que no se hayan producido errores durante la ejecución. En la parte inferior de la imagen, se muestra un ejemplo de log, que incluye la información relacionada con la entrada y salida del modelo, así como cualquier advertencia o error.
- Aquí es importante asegurarse de que todos los archivos y rutas de entrada/salida estén bien configurados, y que el formato de los datos sea compatible con el entrenamiento del modelo (por ejemplo, valores numéricos sin NaN).
Conclusión: Kubeflow es tu mejor aliado
En este workshop, hemos cubierto todo el flujo de trabajo necesario para instalar, configurar y ejecutar un pipeline de machine learning usando Kubeflow. Desde la descarga y configuración hasta la creación de un pipeline con XGBoost, Kubeflow ha demostrado ser una herramienta poderosa y flexible para cualquier desarrollador o data scientist que busque llevar sus modelos a un entorno de producción de manera fluida.
Lo más destacado es cómo Kubeflow está diseñado para integrarse perfectamente con Kubernetes, permitiendo que todo el potencial de tu infraestructura actual se utilice de manera eficiente y escalable. Esto no solo reduce la complejidad operativa, sino que te permite concentrarte en lo más importante: desarrollar y optimizar tus modelos.
Kubeflow es, sin duda, tu mejor aliado para automatizar y escalar tus experimentos de machine learning, y, una vez lo dominas, no hay vuelta atrás. Este es solo el comienzo de lo que puedes lograr con una herramienta que transforma tus modelos en soluciones robustas listas para producción.
¿Quieres seguir conociendo lo último en programación? Síguenos en nuestro Canal de YouTube y Redes Sociales.


